
Let’s return to last week’s post, found here.
I want to start looking at this in smaller chunks, which will hopefully be a little clearer. First, some overall major takeaways:
– E = R ((60 – T) / 60) + C, the formula, for reference.
– Large underdogs should be extremely aggressive early in games, when R (relative strength) is at its largest.
– Underdogs should attempt to use as much of the clock as possible. This is more “conventional” and something I didn’t talk about last week, but it’s a logical extension of what I was talking about. If you have two very mismatched teams, and make them play 100 games, it’s almost certain that the “better” team will win more than it will lose. The larger the sample, the more likely it is to reflect that actual “relative strength”. By using up a clock, the underdog is limiting the sample size “# of plays” from which the relative strength advantage can play out. Using our formula, by bleeding the clock, underdogs are attacking the R value indirectly, using T, instead of going at R itself (scoring points).
– During the game, strategic decisions should incorporate an objective view of how the rest of the game is likely to play out. For large underdogs, this means they should expect to be outscored, and therefore need to be aggressive in scoring points.
Favorites Strategy
I didn’t discuss how this effects the strategy of the Favorite. In the most simple reading, it can be assumed that the Favorite should be more “conservative”. Going back to our Broncos vs. Jaguars example, 3 points is a lot more valuable to Denver than it is to Jacksonville (hence “not all points are equal”). Therefore, given the same FG opportunity as the one we gave Jacksonville (expected points for FG and going for it are equal, purely a risk/reward play), it should elect the LOW risk option (the FG).
That’s because, as I explained above, at any time T, the favorite can expect to outplay the underdog over the rest of the game, i.e. the R value is advantagous. As time goes on, this becomes less of a factor (T declining ultimately takes the R half of the equation to 0).
In general, I agree with this. Large favorites should be content to take whatever points they can get, early in the game.
However, there is a slight wrinkle, one that will appeal to the more aggressive fans. Let’s go back to our graphic for a moment. Here is the range of outcomes at the start of the game: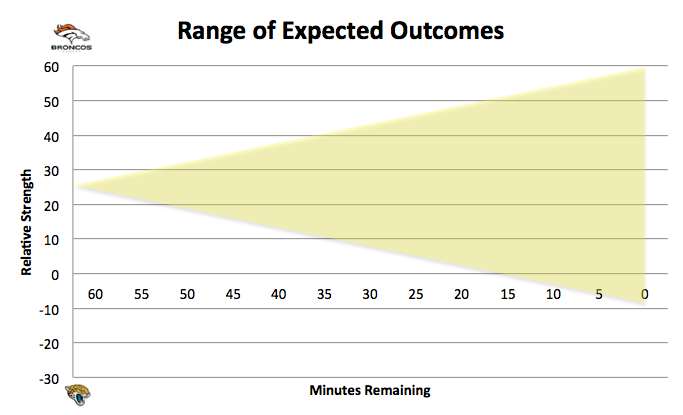
As you can see/remember, if we assume a “random walk” from there, Denver should expect to win a very large percentage of the time. There is a case to be made for being aggressive, though, and hopefully you can see it.
It goes back to when I explained that you can actually “win” the game before the game is over. Assume the same EP-Neutral opportunity above, but this time imagine that gaining 7 points is enough to shift the range of outcomes (yellow shade) entirely above the X-Axis. Would you go for it or kick? Probably go for it, right? After all, if you have a chance to “win the game”, with relatively low risk (still have a heavy advantage if you don’t convert), you should do it.
Obviously, I have to note that this is a purely theoretical situation. During the game, it’s not possible to know EXACTLY where the range of expected outcomes lies. Therefore, we can’t be sure of where the line between 100% win and 99% win is, even if some of us see that final 1% as extremely valuable.
Still, it implies that there are some situations, even if they are hard to identify, where the Favorite should also be aggressive. In general, though, it should take the lower risk strategic options, because it does NOT want to significantly shift R (outside of the specific scenario I just outlined).
Random Walk
I don’t think I made a big enough point of this model in the post last week. There are two ways to view the game, ex-ante, and I think one of them is much better than the other.
1) This is the normal model. Teams start on even ground (Score tied 0 – 0) and we “expect” the course of play to naturally favor one team (the favorite) over the other (the underdog). During actual play, we project that the difference in skill will gradually manifest itself in the score, and ultimately mean victory for the Favorite. That’s the usual way of thinking about it.
What I’ve done is to flip that around a bit.
2) Teams start on UNEVEN ground (R value), and from there we expect a random series of events to occur, though they will be within a range of possible outcomes. This certainly isn’t the “natural” way of thinking about things, but it appeals to me for one very big reason. Can you guess what that is?
I like it because it forces us to accept and recognize the large role of luck and chance in the outcome of the game. Future human events are inherently unpredictable, right? So how do we reconcile that with the first option I outlined above (the normal model)? Isn’t it explicitly forcing us to predict that which is, by its very nature, unpredictable?
The result of this is that we get ridiculous explanations for unexpected outcomes of games. For example, take the Giants-Patriots SB (Helmet Catch). The Patriots were heavy favorites, and yet lost a close game. Why?
– Is it because Eli Manning is just REALLY clutch?
– Is it because the Patriots “choked”?
– Is it because the Giants have more “heart”? or “wanted it more”?
Of course not, those are all ridiculous explanations, and yet they’re a natural outgrowth of the way we normally think of games (option 1).
Now let’s look at the “Random Walk / Ex-Ante Relative Strength” model (the name needs work). Here’s the picture again, just imagine a Patriots logo instead of the Broncos and a Giants logo instead of the Jaguars.
Suddenly there’s no explanation needed for the outcome of the game. Just look at the picture; you can see there’s a section of the yellow shaded area below the X-Axis. If we assume that at time T=60, all future game events will take a random path through the yellow area, then it’s obvious that SOME of those infinite paths will end up in the area below the X-Axis. It just so happens that THIS PARTICULAR run was among those.
Now there’s also obviously some unpredictability in deriving a value for R. It’s very difficult to know just how good each team is and how they match up against each other. However, I’d argue that all of the necessary information for getting an accurate R value is theoretically knowable. Compare that the Normal Model. It requires us to predict future events, which is NOT POSSIBLE, even in theory.
The upshot of the “Random Walk” is that it forces people to confront a lack of “control”. It basically boils the game down to a lottery. That sucks some of the fun out of it, but that doesn’t mean its a less accurate model of analysis.
Similar to last time, I’m going to cut this off prematurely for the sake of time and clarity. Hopefully you’re still with me.

Great piece as always.
Could be a fun exercise to try and calculate an absolute value of R for each team based on whichever stats over whichever sample you think most relevant such that delta-R would be the relative strength for a given game. Obviously it’s unlikely to be particularly accurate, but it could be fun to have a go.
Im considering it, though can’t decide whether its better to use the gambling spreads or something like FO’s DVOAs. Maybe a combination of both.
On Thu, Oct 17, 2013 at 8:16 AM, Eagles Rewind
I’d be inclined to do a DVOA kind of thing, given that no matter how much we want to assume Vegas is an efficient market, it almost certainly isn’t.
It seems like there are some incentives working at cross-purposes here. On one hand, it pays for the underdog to be aggressive, which means taking some shots and increasing the risk for 3 (or even 4) and outs. On the other hand, it pays for the underdog to suck up the clock.
I wonder if there’s some way to resolve this seeming tension?
Another example of an underdog team playing to lose with their conservatism on Thursday night.
4th and Goal at the Seattle 4 yard line, Cardinals kick a field goal down 18 points at the top of the 4th Quarter. Yikes.
> E = R ((60 – T) / 60) + C, the formula, for reference.
If we have to look up what the letters mean, from the other article is it really that useful as a reference? There’s plenty of space to write things out long hand. The formula could be a bit clearer anyway:
The Expected Margin = (Relative Strength) * (Time Remaining) + The Current Margin
> Large underdogs should be extremely aggressive early in games, when R (relative
> strength) is at its largest.
An implicit assumption for your model is that the relative strength is constant, so the notion that R is at its largest at the beginning of the game is nonsense. (The “R ((60 – T) / 60)” term is at its largest at the beginning of the game, but the expected margin of victory may not be, and the win probability certainly won’t be.)
Sure, underdogs should be aggressive early in the game, but, if the game plays out as expected, they should be aggressive throughout the entire game. If the game slips away from them, the underdogs should become more risk tolerant, and if they manage to do better than expected, the underdogs should be more risk averse.
> … Going back to our Broncos vs. Jaguars example, 3 points is a lot more valuable to Denver > than it is to Jacksonville …
Winning a football game is a zero-sum proposition. Therefore any event (including scoring) will have equal and opposite value for the teams.
Denver should be more willing to kick field goals, not because the points are more valuable to them than to Jacksonville, but because Denver is ‘virtually ahead’ and thus prefers the relative certainty of the field goal.
> – Underdogs should attempt to use as much of the clock as possible.
The analysis requires some more sophisticated math, and is proabably outside the scope of this discussion, but in a random walk model luck needs time to have an impact, so the underdogs really only want to burn clock early in the game, or if they get unexpectedly lucky. (That should make sense: in a typical NFL mismatch, at some time in the game the favorite will get a comfortable margin, and then start running the clock, while the underdog is under time pressure.) Since a certain small win is better than a likely large one, in more extreme cases, the favorite may actually be the team that wants to burn clock early.
> After all, if you have a chance to “win the game”, with relatively low risk (still have a heavy
> advantage if you don’t convert), you should do it.
If the situation is that low in risk, you’re going to be chosing between two or three (maybe even four) different ways to ‘win the game’.
This part was incorrect:
> Since a certain small win is better than a likely large one, in more extreme
> cases, the favorite may actually be the team that wants to burn clock early.
As long as the game is tied – like it is at the beginning of the game – the underdog is happy to eat up clock.